Looking at the “5209”-file with my text-editor leafpad I noticed that the bulk of the entries consists of lines begnning with “<” and ending with “>”.
The real “valuable” content of the page doesn´t start with “<” or " <".
So what about eliminating the “<”-lines with sed or awk?
The remainder should be the text one wishes to obtain.
Neither chromium nor firefox display anything at all. Just an empty page.
Despite the fact that viewing the page source code of the (apparently) empty page can be fully displayed.
Most mysterious.
BUT:
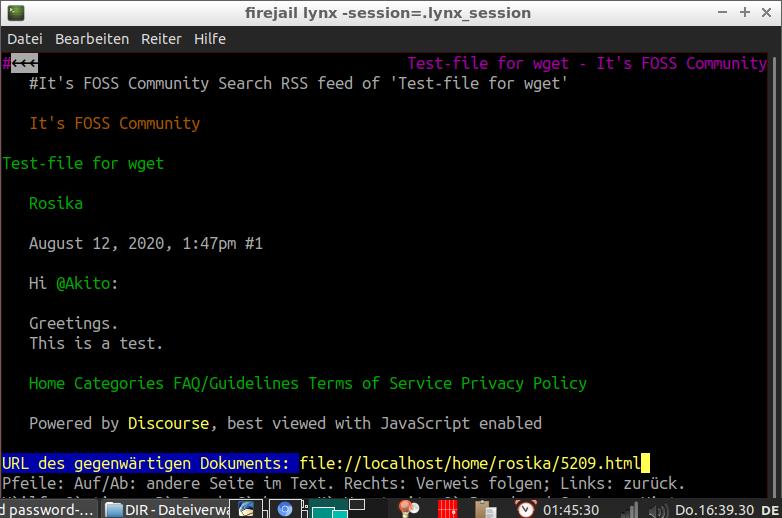
Out of curiosity I tried firing up that 5209-page in the terminal-browser lynx.
To my great astonishment lynx is able to show it properly:
Alas my command sed '/^[< ]/d' output_file.html doesn´t seem to work too well with more content-laden pages.
It leaves a great deal of stuff out.
Originally I tried it just with the example page for @Akito and this one consists of only the message
Hi @Akito
Greetings.
This s a test.
So not much of a challenge there. My command simply depends upon the following pattern:
delete every line beginning with “<” or " <".
But it tuned out that part of the real message content doesn´t fit that pattern.
So lynx-browser to the rescue once more
I just tried it again with a more demanding page and lynx could reproduce the downloaded file perfectly!
No success with chromium and firefox. Here again they just display an empty page.
It still puzzles me.
Press F12 when you are on the private message. Then go to the Network tab and look for the request initiated by BrowserTabChild*
I eventually found the BrowserTabChild-entry in firefox.
Orginally in tried to find that in chromium but as I didn´t succeed I (rather foolishly) used another entry which deemed to me it might work. But of course it didn´t , at least not the way it was intended.
Alas I cannot remember which entry I copied as the curl-command. So I cannot reproduce the behaviour.
At any rate I used “copy as cURL” and let it run.
But the download (or what else it was) didn´t seem to finish. It may well be possible that it was repeated again and again by the look of the termial output. Very strange.
Anyhow as it never came to a standstill I looked up ps aux | grep curl
but “curl” as a running process didn´t seem to exist.
So I tried “CTRL+c”. No success. Then “CTRL+d”. Still no success. The process of whatever it was kept on going.
As final step I resorted to closing the terminal by clicking on the upper right “X”.
I haven´t got the slightest idea what I was doing - quite contrary to my habit, I can assure you.
So my question would be:
As I initiated the curl-command without setting the “-o” or “-O” parameter the output would have been written to stdout , i.e. the terminal, right?
As I had to abort the process it was never terminated and no result was written to the terminal.
But where is it? Or did it end up being sent into nirvana?
A bit of an odd question, I´m sure. Excuse me for that.
Well, I cannot reproduce it as I said but what about a more general question:
If I download a huge file with curl but abort the download before it has finished. And I abort it by closing the terminal window.
No “-o” or “-O” parameters set.
Is part of the download stored anywhere?
I would guess not as no output file has been defined. Or am I totally wrong here?
as an additional info I just want to let you know:
I found out that not only lynx but also w3m has no problems displaying the page that curl got us.
It seems that for whatever reason text-based browsers are perfectly suited for that.
The graphical ones (I tested firefox, chromium and falkon) always produce a seemingly empty page.
Just “seemingly” because the page source text is still available.
As a solution, or rather workaround, for the initial question of how to download password-protected pages this one seems to be the most practicable:
For displaying that downloaded file ([…].html) use either w3m or lynx.
You may even try dillo although I haven´t tested it yet.
Thanks to @01101111 for the hint.
References:
Step 3:
To save the downloaded page for documentation and archival purposes:
Here´s an example using lynx:
lynx -dump "example_page.html" > file.txt
OR:
lynx "example_page.html" and then from within the browser press “p” and choose “save in local file”.
The dump-command turns out to be better suited for me as at the end of the file a compendium of all links used by the page is appended. Very nice.
So thanks so much to all of you who have worked so hard to get this problem solved.