Hi to all of you again, 
thanks a lot for all of your suggestions. 
@nevj :
Thanks for mentioning it.
In fact I stumbled upon yesterday as well  :
:
mpstat Command in Linux with Examples - GeeksforGeeks .
Just tried it out:
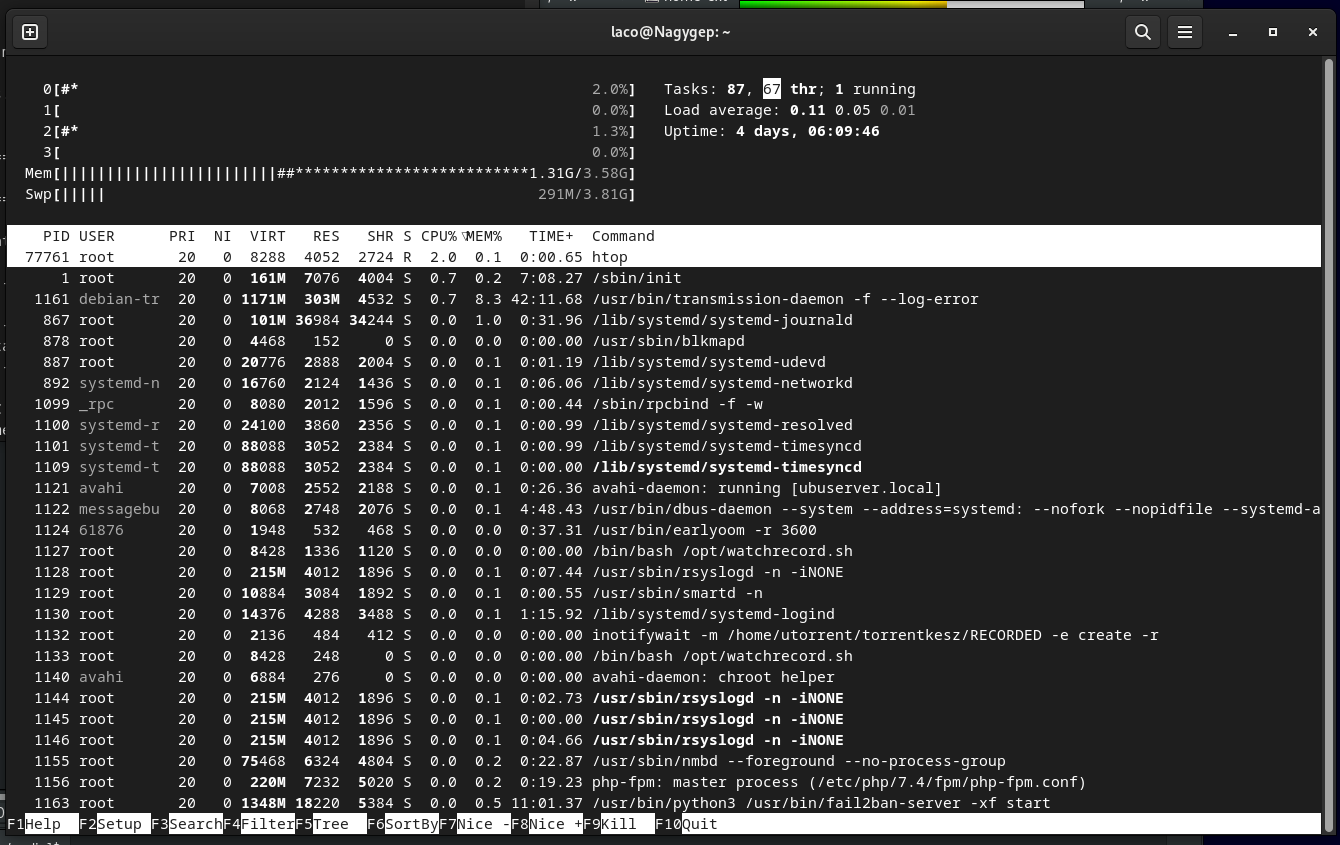
Linux 5.15.0-119-generic (rosika-Lenovo-H520e) 11.09.2024 _x86_64_ (4 CPU)
13:47:01 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:47:01 all 6,69 0,02 2,42 6,03 0,00 0,06 0,00 0,00 0,00 84,78
…
Thanks for pointing that out, Neville.
@abhishek :
Thanks a lot, Abhishek.
The sar command was indeed new to me, I have to admit.
I got this message though:
sar -u
Cannot open /var/log/sysstat/sa11: No such file or directory
Please check if data collecting is enabled
According to fosslinux :
Sometimes when attempting to use ‘sar -u’ to view CPU usage, users may encounter an error stating that data collection is not enabled.
This error message indicates that the system activity data required for ‘sar’ is not being collected or stored. To fix this issue, we need to enable data collecting and configure the sysstat package correctly.
To enable data collecting, open the /etc/default/sysstat configuration file using your preferred text editor:
Find the following line in the configuration file:
ENABLED="false"
Change the value from “false” to “true”:
ENABLED="true"
Save the changes and exit the text editor.
Also:
To configure the data collection interval, edit the /etc/cron.d/sysstat file:
By default, the sysstat package collects data every 10 minutes. To change the interval, find the following line:
5-55/10 * * * * root command -v debian-sa1 > /dev/null && debian-sa1 1 1
Replace ‘/10’ with your desired interval (e.g., ‘/5’ for a 5-minute interval):
5-55/5 * * * * root command -v debian-sa1 > /dev/null && debian-sa1 1 1
Save the changes and exit the text editor.
To apply the changes, restart the sysstat service:
sudo systemctl restart sysstat
I´ll still have to do that.
@kovacslt :
Yes, that´s exactly what I need. Thanks, László.
Also thanks @TypeHrishi and @callpaul.eu for your posts.
@all:
Well, what I´d like to achieve is getting the CPU value detached from any momentary snapshot. Like smoothing out the variability.
Doing a bit of further research on the matter I came up with this command yesterday (ChatGPT helped a lot with it, I have to admit ):
top -bn10 | grep "Cpu(s)" | awk '{u+=$2; s+=$4} END {print "Average CPU usage:", u/NR + s/NR, "%"}'
Explanation:
-
The top command provides real-time system stats like CPU usage, memory usage, etc.
-b: This flag tells top to run in batch mode, which outputs the data to the terminal instead of running interactively.
-n10: This means the command will run 10 iterations of top. Instead of running indefinitely like it does in interactive mode, it captures data 10 times and then stops.
-
grep “Cpu(s)”: This filters the output of top and selects only the lines containing the string "Cpu(s)
-
awk:
u+=$2; s+=$4:
$2: Refers to the second field in the output (user CPU percentage).
$4: Refers to the fourth field in the output (system CPU percentage).
u+=$2: This adds the value of the second field ($2, user CPU usage) to the variable u. This means u accumulates the user CPU usage across all 10 iterations.
s+=$4: Similarly, this adds the value of the fourth field ($4, system CPU usage) to the variable s. This means s accumulates the system CPU usage.
At the end of this loop, u will hold the total user CPU usage from all 10 snapshots, and s will hold the total system CPU usage.
-
END {}: This block is executed after awk has processed all the input lines.
NR: A special variable in awk that represents the number of records (or lines) processed. In this case, it will be 10, since top was run 10 times.
u/NR: This calculates the average user CPU usage by dividing the total accumulated value u by the number of records (NR = 10).
s/NR: Similarly, this calculates the average system CPU usage.
u/NR + s/NR: This adds the average user and system CPU usage together to get the overall CPU usage.
print “Average CPU usage:”, …: This prints the final result in a readable format.
Note:
By default, top updates its statistics roughly once every 3 seconds when running in batch mode. This means that each iteration of top takes about 3 seconds to complete.
So the command took roughly 30 seconds to finish.
I ran it 3 times in a row:
rosika@rosika-Lenovo-H520e ~> top -bn10 | grep "Cpu(s)" | awk '{u+=$2; s+=$4} END {print "Average CPU usage:", u/NR + s/NR, "%"}'
Average CPU usage: 2.8 %
rosika@rosika-Lenovo-H520e ~> top -bn10 | grep "Cpu(s)" | awk '{u+=$2; s+=$4} END {print "Average CPU usage:", u/NR + s/NR, "%"}'
Average CPU usage: 3.2 %
rosika@rosika-Lenovo-H520e ~> top -bn10 | grep "Cpu(s)" | awk '{u+=$2; s+=$4} END {print "Average CPU usage:", u/NR + s/NR, "%"}'
Average CPU usage: 2.9 %
rosika@rosika-Lenovo-H520e ~> bc -l
bc 1.07.1
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
(2.8+3.2+2.9)/3
2.96666666666666666666
quit
… and then calculated the average.
I guess this should provide a pretty accurate notion of CPU usage in a more or less idle state.
Of course, I didn´t start any other processes in the meantime, just let the command run three times.
Thanks so much to all of you for your help.
Many greetings from Rosika