Hi altogether,
I´d very much like to ask your opinion about a curious matter.
I´ve downloaded an e-book from distrowatch “Bash Special Characters” as a pdf-file (via tradepub.com).
You may find it here: https://www.tradepub.com/free/w_howt03/prgm.cgi?a=1 .
For the download I received a link via e-mail which I copied into my browser and the download started.
Out of curiosity I copied the link provided within the browser (for initiating the download manually in case the automatism failed) and
started a second download via terminal with wget.
Both ways worked well but when I performed an md5sum check on both files I got different results:
These are the two PDFs (I renamed them in order to make the whole thing clearer):
-rw-rw-r-- 1 rosika2 rosika2 1,6M Jul 29 16:57 index.pdf # via wget
-rw-rw-r-- 1 rosika2 rosika2 1,6M Jul 29 16:55 w_howt03.pdf # via browser
But the command md5sum *.pdf
got me the following results:
47e4dd0b6cded36edd527480774fc6ff index.pdf
8c5d48f7db53bbf8f8eecb02365b1ea6 w_howt03.pdf
Hmm. They should be identical. 
As a next step I extracted the text-part with pdftotext. Now the content of my folder looked like this:
-rw-rw-r-- 1 rosika2 rosika2 1,6M Jul 29 16:57 index.pdf
-rw-rw-r-- 1 rosika2 rosika2 17K Jul 29 18:02 index.txt
-rw-rw-r-- 1 rosika2 rosika2 1,6M Jul 29 16:55 w_howt03.pdf
-rw-rw-r-- 1 rosika2 rosika2 17K Jul 29 18:03 w_howt03.txt
Performing an md5sum check on the resulting text-files got me this:
md5sum *.txt
e4778d644c47203ff7ef31ad6e766701 index.txt
e4778d644c47203ff7ef31ad6e766701 w_howt03.txt
Wow. The text part is completely identical. So the difference must lie somewhere else.
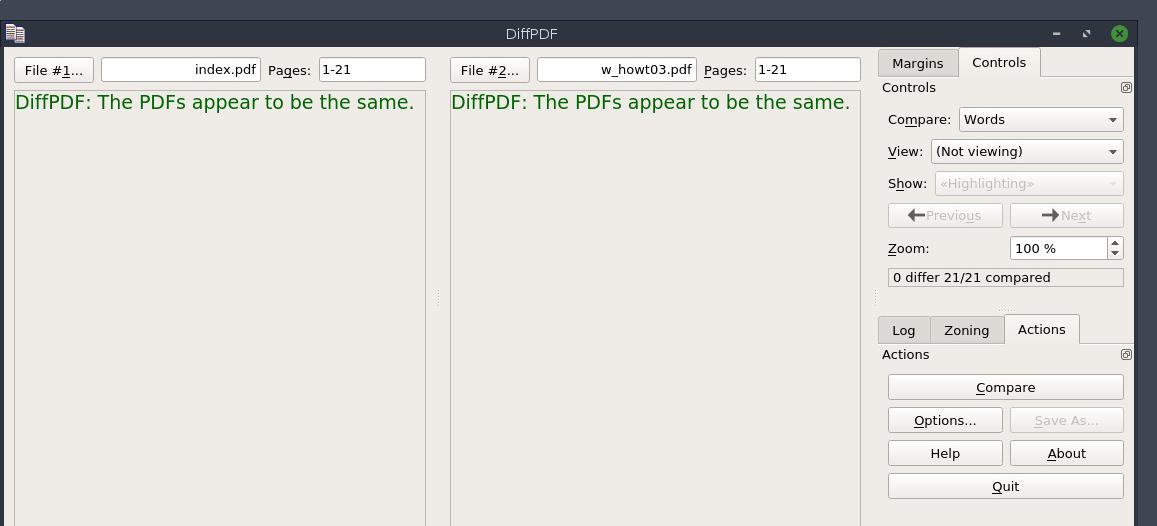
Looking through the PDFs manually with evince showed no visible difference either.
As a last step I resorted to pdfinfo to see if I could spot anything there.
And bang! There´s just one single difference in the output:
File size: 1645832 bytes # howt03.pdf
File size: 1645848 bytes # index.pdf; the one I downloaded manually via wget
It seems that the copy I got via wget is exactly 16 bytes larger than the one I downloaded with the browser.
It may not be especially important but it seems interesting. Why may that be? 
Does anyone have any ideas?
Thanks in advance.
Greetings.
Rosika