Once in a while I ssh into a server running at a very small company. I deployed them a Seafile server with CODE (Collabora Online Dev. Ed.).
It’s powered by Debian Buster.
Sometimes I run update&&upgrade, check logs, SMART attributes of disks, but that’s all.
It just runs and serves.
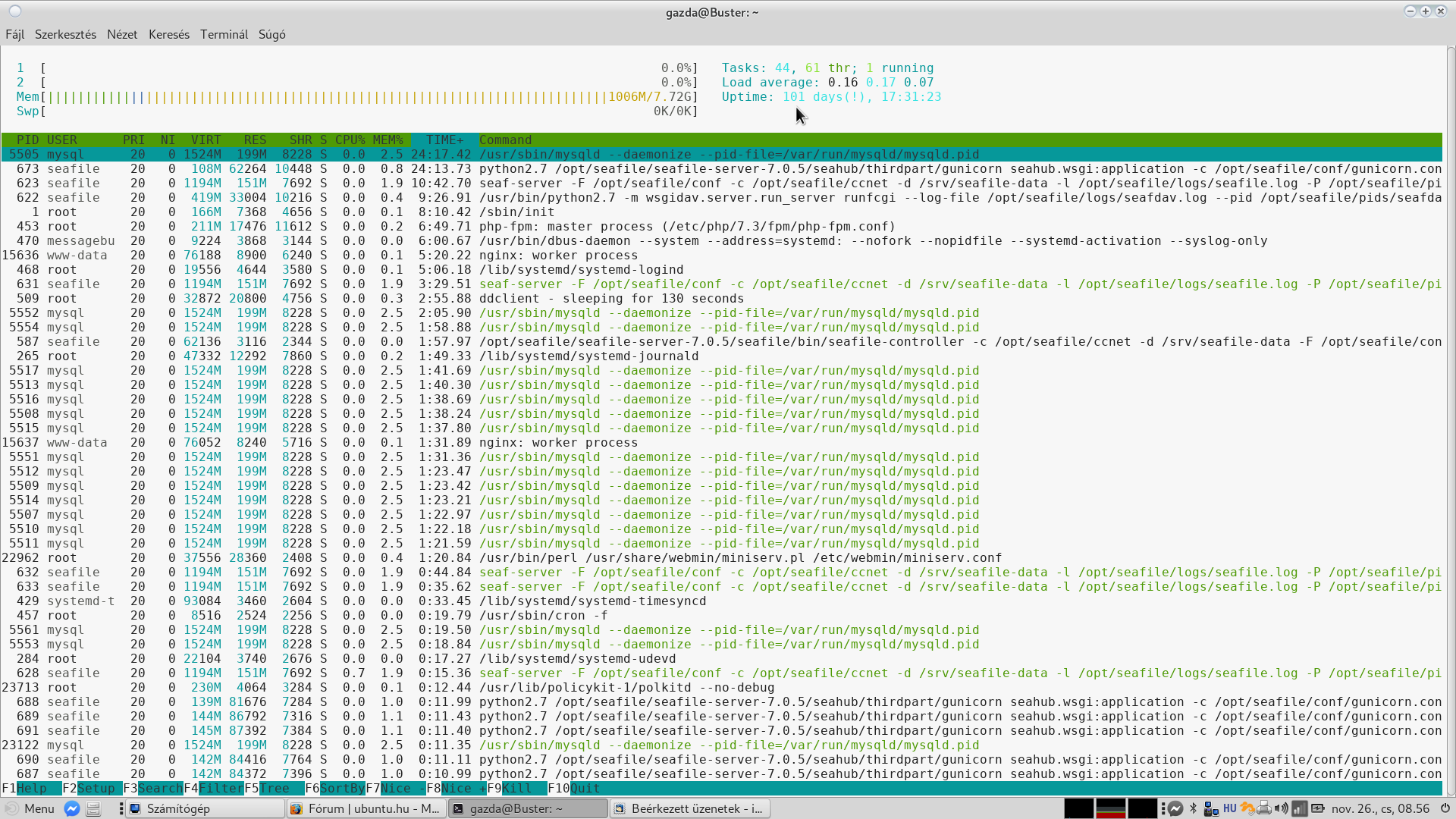
Today I looked at htop and noticed the exclamation mark beside the uptime.
Now it’s on 4.19.0-8 kernel, and it got an update to 4.19.0-12, so I’m going to reboot it soon.
But hey, it worked for 101 days uninterrupted!
- at the start of the pandemic - it was doing extra work (running some PHP to analyse and graph VPN usage/demand - when the number of staff doing “WFH” increased exponentially) - so I boosted it from 2 GB RAM to 8 GB and gave it another pair of vCPU’s… all online as its a VMware ESX guest piece of cake …
I guess I should patch it - but I’m “ol’ skool” - I still remember we only patched stuff if the specific patch fixed something that was broken that we needed working…
At another customer - I’ve got a few UNIX or Linux servers with something insane like 2000+ days uptime…
I did have one of my NTC CHIP computers up for over 365 days (running off a LiPo as a UPS)…
The last time all devices were officially shut down, were when there were electric engineers at the place, to repair some power related issue, which required the power to be turned off for everyone. I guess the 133 days is related to that day, else it would be running for even longer.
Depending on the use, my personal (non-commercial, non-corporate, non-production) servers usually run a very long time as well, even though I do not put that much effort in them.
Other Raspberry Pis restart more frequently, however those aren’t classic servers or they are only used sometimes and not every day, so a restart has a different meaning in those cases.
That’s stuff I can only dream about since deregulation and Spectrum,(Charter Communications) took over Brighthouse networks.
If I get 4~5 hours uptime I’m doing well but it’s often as low as 8Kb as ‘high’ as 45Mb for 40 minutes or so. Wen’t ‘off’ just as I was typing this, had to re-boot everything 1.5 hours later to complete. Really pissed with Charter upper level BS managers
 - at the start of the pandemic - it was doing extra work (running some PHP to analyse and graph VPN usage/demand - when the number of staff doing “WFH” increased exponentially) - so I boosted it from 2 GB RAM to 8 GB and gave it another pair of vCPU’s… all online as its a VMware ESX guest
- at the start of the pandemic - it was doing extra work (running some PHP to analyse and graph VPN usage/demand - when the number of staff doing “WFH” increased exponentially) - so I boosted it from 2 GB RAM to 8 GB and gave it another pair of vCPU’s… all online as its a VMware ESX guest