I have a rather old and battered book which contains an essay by Dorothy Sayers that I rather like. The pages are yellowing, and the print quality is poor, so I decided to try and resurrect my favourite essay into a modern format.
The steps were
- Scan each page of the document with
xsane. The quality was poor, for example here is the image from the fourth page

- Process that image with tesseract
tesseract image-0004.png image-004
The first argument is the image , the second argument is the output file… it appends .txt , so we get image-004.txt.
The output looks like this
THE GREAT. MYSTERY.
its'for it-is what God wants for'us:and,.as St:
Paul says, no created thing, whether of. time,
spice. or split, can sepafate us from His love.
Bhit do we truly want it? At bottom—yes,
wé do, for itis the end for-which we were made
and without which We caniot be happy ot com-
plete, “In. every soul-that shall be saved,”
said the Lady Julian of Norwich;.“ there is a
godly’will that never assented to sin, nor ever
shall,” ‘and-it is this will- which ‘has to be set
free so that it may becomeé united to: God,
* * *
That is just the first paragraph. As you can see it is ‘noisy’. It gets letters wrong, puts an accent over ‘e’, and inserts punctuation that is not there. That example is one of the worst paragraphs.
Tesseract deals with the two facing pages in the scanned image OK.
- So to fix that I had to hand edit the .txt file output of tesseract for each page. I used vi. The cleaned up paragraph above looks like this
it; for it is what God wants for us and, as St.
Paul says, no created thing, whether of time,
space or spirit, can separate us from His love.
But do we truly want it? At bottom — yes,
we do, for it is the end for which we were made
and without which we cannot be happy or com-
plete, “In every soul that shall be saved,”
said the Lady Julian of Norwich, “there is a
godly will that never assented to sin, nor ever
shall,” ‘and it is this will which has to be set
free so that it may become united to God,
* * *
OK, do that for all five pages, then
- Read all five pages into one .md file.
There are still some fixes needed
- setup the heading
- get rid of the minuses in ‘xxx-xxx’ words which span line-breaks
- space out those
* * *breaks - put the italics into .md format
- add a References section at the end
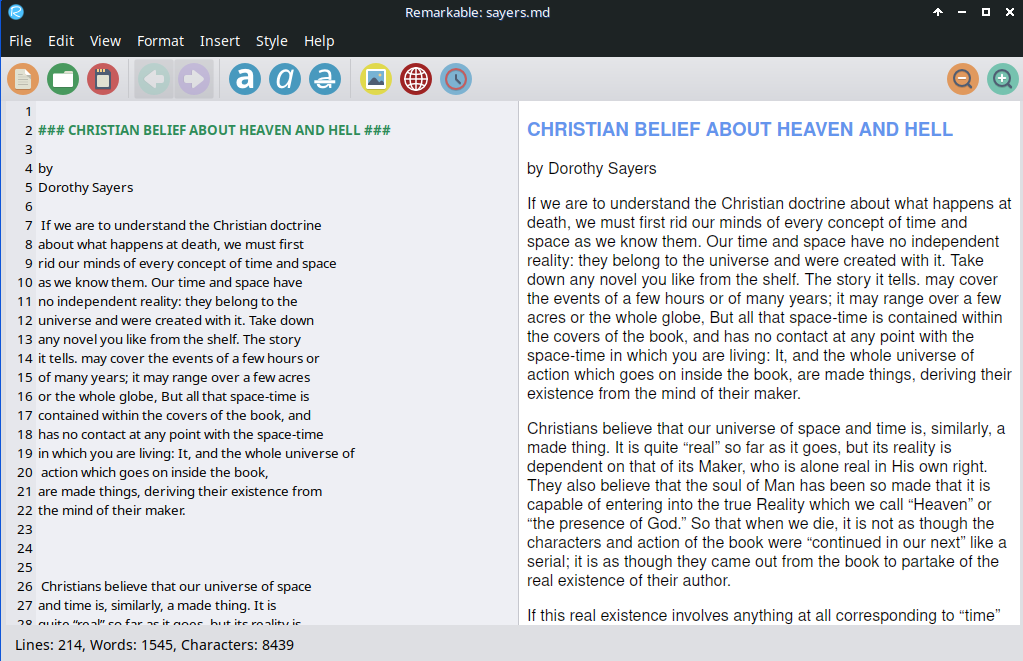
It took a couple of days of fiddling, but the result is very satisfactory ( for me) . Here is a sample as seen in the remarkable .md viewer
There are other OCR apps than tesseract available in Linux, including one that is a GUI for tesseract.
Tesseract is the leading one… it supports many languages.
If anyone in interested in the actual Sayers essay, there is a copy of my sayers.md file here
and the book from which it came is
I believe it may still be copyrighted. You are allowed to take one copy for private use.