Waking this up again…
I had some files that start with what I thought was '" ’ (i.e. double quote, followed by space).
BUT NO! perl rename / prename wasn’t finding " in the files and giving up. But I was wrong!
This is the char :
"
Yeah - it looks like double quote followed by a space - but - it’s a SINGLE char - how is that possible?
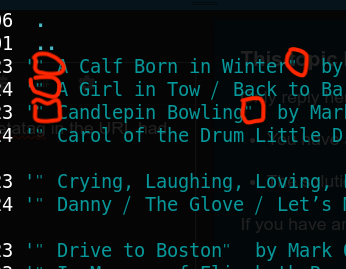
Here’s my list of files :
-rw-rw-r-- 1 x x 6350349 Nov 8 2023 '"A Calf Born in Winter" by Khruangbin from THE HOLDOVERS [GIkzMStIMcE].mp3'
-rw-rw-r-- 1 x x 7645989 Jan 7 2024 '"A Girl in Tow ⧸ Back to Barton" by Mark Orton from THE HOLDOVERS [9c0MG3FW-zk].mp3'
-rw-rw-r-- 1 x x 4276173 Nov 29 2023 '"Candlepin Bowling" by Mark Orton from THE HOLDOVERS [eHY1FqVemMY].mp3'
-rw-rw-r-- 1 x x 2404533 Jan 15 2024 '"Carol of the Drum Little Drummer Boy" by TRapp Family Singers from THE HOLDOVERS [SuRVpOaJFjo].mp3'
-rw-rw-r-- 1 x x 5413581 Nov 19 2023 '"Crying, Laughing, Loving, Lying" by Labi Siffre from THE HOLDOVERS [J3i5qQnFPNA].mp3'
-rw-rw-r-- 1 x x 3851229 Jan 7 2024 '"Danny ⧸ The Glove ⧸ Let’s Make the Best of It" by Mark Orton from THE HOLDOVERS [TM_MTZoLU_g].mp3'
-rw-rw-r-- 1 x x 3818253 Nov 30 2023 '"Drive to Boston" by Mark Orton from THE HOLDOVERS [CvhkOjHneoA].mp3'
-rw-rw-r-- 1 x x 13852653 Nov 30 2023 '"In Memory of Elizabeth Reed" by Allman Brothers Band from THE HOLDOVERS [WovGxE7Zdls].mp3'
-rw-rw-r-- 1 x x 3467445 Jan 22 2024 '"It'\''s Christmas!" by Mark Orton from THE HOLDOVERS [cqfpXF_5iI8].mp3'
-rw-rw-r-- 1 x x 5906253 Jan 15 2024 '"Jingle Bells" by Herb Alpert & The Tijuana Brass from THE HOLDOVERS [kw0tckOotJY].mp3'
-rw-rw-r-- 1 x x 6009141 Jan 7 2024 '"Knock Three Times" by Tony and Orlando Dawn from THE HOLDOVERS [i24KFFcTjrE].mp3'
-rw-rw-r-- 1 x x 5948661 Jan 21 2024 '"Medley" by The Swingle Sisters from THE HOLDOVERS [VUUP8zkAeqE].mp3'
-rw-rw-r-- 1 x x 3333957 Jan 7 2024 '"Nursing Home" by Mark Orton from THE HOLDOVERS [M0kDugwntwk].mp3'
-rw-rw-r-- 1 x x 1398837 Dec 1 2023 '"Primal Architecture" by Mark Orton from THE HOLDOVERS [RbYViT5pUqQ].mp3'
-rw-rw-r-- 1 x x 7884621 Dec 31 2023 '"See Ya ⧸ Into the Unknown" by Mark Orton from THE HOLDOVERS [INNERPfbGfo].mp3'
-rw-rw-r-- 1 x x 11699997 Jan 7 2024 '"Silent Night" by The Temptations from THE HOLDOVERS [5sjH7GuCKTU].mp3'
-rw-rw-r-- 1 x x 3580221 Nov 19 2023 '"Silver Joy" by Damien Jurado from THE HOLDOVERS [l_G7tXzTHVE].mp3'
-rw-rw-r-- 1 x x 8082285 Jan 1 2024 '"The Glove ⧸ Now He’s History ⧸ 5⧸4 for Constantine" by Mark Orton from THE HOLDOVERS [PT-1lGa3kbY].mp3'
-rw-rw-r-- 1 x x 4765677 Jan 22 2024 '"The Most Wonderful Time of the Year" by Andy Williams from THE HOLDOVERS [-R_5Zfx2c6Y].mp3'
-rw-rw-r-- 1 x x 9822213 Nov 29 2023 '"The Time Has Come Today" by The Chamber Brothers from THE HOLDOVERS [cPxwLS0jFkc].mp3'
-rw-rw-r-- 1 x x 3246189 Nov 19 2023 '"The Wind" by Cat Stevens from THE HOLDOVERS [CXNAYyKnkv4].mp3'
-rw-rw-r-- 1 x x 5409501 Nov 27 2023 '"Venus" by Shocking Blue from THE HOLDOVERS [amv5yOfVM2U].mp3'
-rw-rw-r-- 1 x x 3591909 Nov 14 2023 '"When Winter Comes" by Artie Shaw from THE HOLDOVERS [7KH3fPzx0ew].mp3'
-rw-rw-r-- 1 x x 4103853 Jan 22 2024 '"White Christmas" by The Swingle Singers from THE HOLDOVERS [U042cBcUrLQ].mp3'
Then a dry run :
╭─x@titan ~/tmp/holdovers
╰─➤ rename -n 's/\"//' *
rename("A Calf Born in Winter" by Khruangbin from THE HOLDOVERS [GIkzMStIMcE].mp3, A Calf Born in Winter" by Khruangbin from THE HOLDOVERS [GIkzMStIMcE].mp3)
rename("A Girl in Tow ⧸ Back to Barton" by Mark Orton from THE HOLDOVERS [9c0MG3FW-zk].mp3, A Girl in Tow ⧸ Back to Barton" by Mark Orton from THE HOLDOVERS [9c0MG3FW-zk].mp3)
rename("Candlepin Bowling" by Mark Orton from THE HOLDOVERS [eHY1FqVemMY].mp3, Candlepin Bowling" by Mark Orton from THE HOLDOVERS [eHY1FqVemMY].mp3)
rename("Carol of the Drum Little Drummer Boy" by TRapp Family Singers from THE HOLDOVERS [SuRVpOaJFjo].mp3, Carol of the Drum Little Drummer Boy" by TRapp Family Singers from THE HOLDOVERS [SuRVpOaJFjo].mp3)
rename("Crying, Laughing, Loving, Lying" by Labi Siffre from THE HOLDOVERS [J3i5qQnFPNA].mp3, Crying, Laughing, Loving, Lying" by Labi Siffre from THE HOLDOVERS [J3i5qQnFPNA].mp3)
rename("Danny ⧸ The Glove ⧸ Let’s Make the Best of It" by Mark Orton from THE HOLDOVERS [TM_MTZoLU_g].mp3, Danny ⧸ The Glove ⧸ Let’s Make the Best of It" by Mark Orton from THE HOLDOVERS [TM_MTZoLU_g].mp3)
rename("Drive to Boston" by Mark Orton from THE HOLDOVERS [CvhkOjHneoA].mp3, Drive to Boston" by Mark Orton from THE HOLDOVERS [CvhkOjHneoA].mp3)
rename("In Memory of Elizabeth Reed" by Allman Brothers Band from THE HOLDOVERS [WovGxE7Zdls].mp3, In Memory of Elizabeth Reed" by Allman Brothers Band from THE HOLDOVERS [WovGxE7Zdls].mp3)
rename("It's Christmas!" by Mark Orton from THE HOLDOVERS [cqfpXF_5iI8].mp3, It's Christmas!" by Mark Orton from THE HOLDOVERS [cqfpXF_5iI8].mp3)
rename("Jingle Bells" by Herb Alpert & The Tijuana Brass from THE HOLDOVERS [kw0tckOotJY].mp3, Jingle Bells" by Herb Alpert & The Tijuana Brass from THE HOLDOVERS [kw0tckOotJY].mp3)
rename("Knock Three Times" by Tony and Orlando Dawn from THE HOLDOVERS [i24KFFcTjrE].mp3, Knock Three Times" by Tony and Orlando Dawn from THE HOLDOVERS [i24KFFcTjrE].mp3)
rename("Medley" by The Swingle Sisters from THE HOLDOVERS [VUUP8zkAeqE].mp3, Medley" by The Swingle Sisters from THE HOLDOVERS [VUUP8zkAeqE].mp3)
rename("Nursing Home" by Mark Orton from THE HOLDOVERS [M0kDugwntwk].mp3, Nursing Home" by Mark Orton from THE HOLDOVERS [M0kDugwntwk].mp3)
rename("Primal Architecture" by Mark Orton from THE HOLDOVERS [RbYViT5pUqQ].mp3, Primal Architecture" by Mark Orton from THE HOLDOVERS [RbYViT5pUqQ].mp3)
rename("See Ya ⧸ Into the Unknown" by Mark Orton from THE HOLDOVERS [INNERPfbGfo].mp3, See Ya ⧸ Into the Unknown" by Mark Orton from THE HOLDOVERS [INNERPfbGfo].mp3)
rename("Silent Night" by The Temptations from THE HOLDOVERS [5sjH7GuCKTU].mp3, Silent Night" by The Temptations from THE HOLDOVERS [5sjH7GuCKTU].mp3)
rename("Silver Joy" by Damien Jurado from THE HOLDOVERS [l_G7tXzTHVE].mp3, Silver Joy" by Damien Jurado from THE HOLDOVERS [l_G7tXzTHVE].mp3)
rename("The Glove ⧸ Now He’s History ⧸ 5⧸4 for Constantine" by Mark Orton from THE HOLDOVERS [PT-1lGa3kbY].mp3, The Glove ⧸ Now He’s History ⧸ 5⧸4 for Constantine" by Mark Orton from THE HOLDOVERS [PT-1lGa3kbY].mp3)
rename("The Most Wonderful Time of the Year" by Andy Williams from THE HOLDOVERS [-R_5Zfx2c6Y].mp3, The Most Wonderful Time of the Year" by Andy Williams from THE HOLDOVERS [-R_5Zfx2c6Y].mp3)
rename("The Time Has Come Today" by The Chamber Brothers from THE HOLDOVERS [cPxwLS0jFkc].mp3, The Time Has Come Today" by The Chamber Brothers from THE HOLDOVERS [cPxwLS0jFkc].mp3)
rename("The Wind" by Cat Stevens from THE HOLDOVERS [CXNAYyKnkv4].mp3, The Wind" by Cat Stevens from THE HOLDOVERS [CXNAYyKnkv4].mp3)
rename("Venus" by Shocking Blue from THE HOLDOVERS [amv5yOfVM2U].mp3, Venus" by Shocking Blue from THE HOLDOVERS [amv5yOfVM2U].mp3)
rename("When Winter Comes" by Artie Shaw from THE HOLDOVERS [7KH3fPzx0ew].mp3, When Winter Comes" by Artie Shaw from THE HOLDOVERS [7KH3fPzx0ew].mp3)
rename("White Christmas" by The Swingle Singers from THE HOLDOVERS [U042cBcUrLQ].mp3, White Christmas" by The Swingle Singers from THE HOLDOVERS [U042cBcUrLQ].mp3)
Then a final run (2x) :
╭─x@titan ~/tmp/holdovers
╰─➤ ls -al
total 132732
drwxrwxr-x 2 x x 4096 Dec 14 20:49 .
drwxrwxr-x 35 x x 4096 Dec 14 18:01 ..
-rw-rw-r-- 1 x x 6350349 Nov 8 2023 'A Calf Born in Winter by Khruangbin from THE HOLDOVERS [GIkzMStIMcE].mp3'
-rw-rw-r-- 1 x x 7645989 Jan 7 2024 'A Girl in Tow ⧸ Back to Barton by Mark Orton from THE HOLDOVERS [9c0MG3FW-zk].mp3'
-rw-rw-r-- 1 x x 4276173 Nov 29 2023 'Candlepin Bowling by Mark Orton from THE HOLDOVERS [eHY1FqVemMY].mp3'
-rw-rw-r-- 1 x x 2404533 Jan 15 2024 'Carol of the Drum Little Drummer Boy by TRapp Family Singers from THE HOLDOVERS [SuRVpOaJFjo].mp3'
-rw-rw-r-- 1 x x 5413581 Nov 19 2023 'Crying, Laughing, Loving, Lying by Labi Siffre from THE HOLDOVERS [J3i5qQnFPNA].mp3'
-rw-rw-r-- 1 x x 3851229 Jan 7 2024 'Danny ⧸ The Glove ⧸ Let’s Make the Best of It by Mark Orton from THE HOLDOVERS [TM_MTZoLU_g].mp3'
-rw-rw-r-- 1 x x 3818253 Nov 30 2023 'Drive to Boston by Mark Orton from THE HOLDOVERS [CvhkOjHneoA].mp3'
-rw-rw-r-- 1 x x 13852653 Nov 30 2023 'In Memory of Elizabeth Reed by Allman Brothers Band from THE HOLDOVERS [WovGxE7Zdls].mp3'
-rw-rw-r-- 1 x x 3467445 Jan 22 2024 'It'\''s Christmas! by Mark Orton from THE HOLDOVERS [cqfpXF_5iI8].mp3'
-rw-rw-r-- 1 x x 5906253 Jan 15 2024 'Jingle Bells by Herb Alpert & The Tijuana Brass from THE HOLDOVERS [kw0tckOotJY].mp3'
-rw-rw-r-- 1 x x 6009141 Jan 7 2024 'Knock Three Times by Tony and Orlando Dawn from THE HOLDOVERS [i24KFFcTjrE].mp3'
-rw-rw-r-- 1 x x 5948661 Jan 21 2024 'Medley by The Swingle Sisters from THE HOLDOVERS [VUUP8zkAeqE].mp3'
-rw-rw-r-- 1 x x 3333957 Jan 7 2024 'Nursing Home by Mark Orton from THE HOLDOVERS [M0kDugwntwk].mp3'
-rw-rw-r-- 1 x x 1398837 Dec 1 2023 'Primal Architecture by Mark Orton from THE HOLDOVERS [RbYViT5pUqQ].mp3'
-rw-rw-r-- 1 x x 7884621 Dec 31 2023 'See Ya ⧸ Into the Unknown by Mark Orton from THE HOLDOVERS [INNERPfbGfo].mp3'
-rw-rw-r-- 1 x x 11699997 Jan 7 2024 'Silent Night by The Temptations from THE HOLDOVERS [5sjH7GuCKTU].mp3'
-rw-rw-r-- 1 x x 3580221 Nov 19 2023 'Silver Joy by Damien Jurado from THE HOLDOVERS [l_G7tXzTHVE].mp3'
-rw-rw-r-- 1 x x 8082285 Jan 1 2024 'The Glove ⧸ Now He’s History ⧸ 5⧸4 for Constantine by Mark Orton from THE HOLDOVERS [PT-1lGa3kbY].mp3'
-rw-rw-r-- 1 x x 4765677 Jan 22 2024 'The Most Wonderful Time of the Year by Andy Williams from THE HOLDOVERS [-R_5Zfx2c6Y].mp3'
-rw-rw-r-- 1 x x 9822213 Nov 29 2023 'The Time Has Come Today by The Chamber Brothers from THE HOLDOVERS [cPxwLS0jFkc].mp3'
-rw-rw-r-- 1 x x 3246189 Nov 19 2023 'The Wind by Cat Stevens from THE HOLDOVERS [CXNAYyKnkv4].mp3'
-rw-rw-r-- 1 x x 5409501 Nov 27 2023 'Venus by Shocking Blue from THE HOLDOVERS [amv5yOfVM2U].mp3'
-rw-rw-r-- 1 x x 3591909 Nov 14 2023 'When Winter Comes by Artie Shaw from THE HOLDOVERS [7KH3fPzx0ew].mp3'
-rw-rw-r-- 1 x x 4103853 Jan 22 2024 'White Christmas by The Swingle Singers from THE HOLDOVERS [U042cBcUrLQ].mp3'
Above files were grabbed using youtube-dl or yt-dlp… soundtrack for the movie “The Holdovers”…